
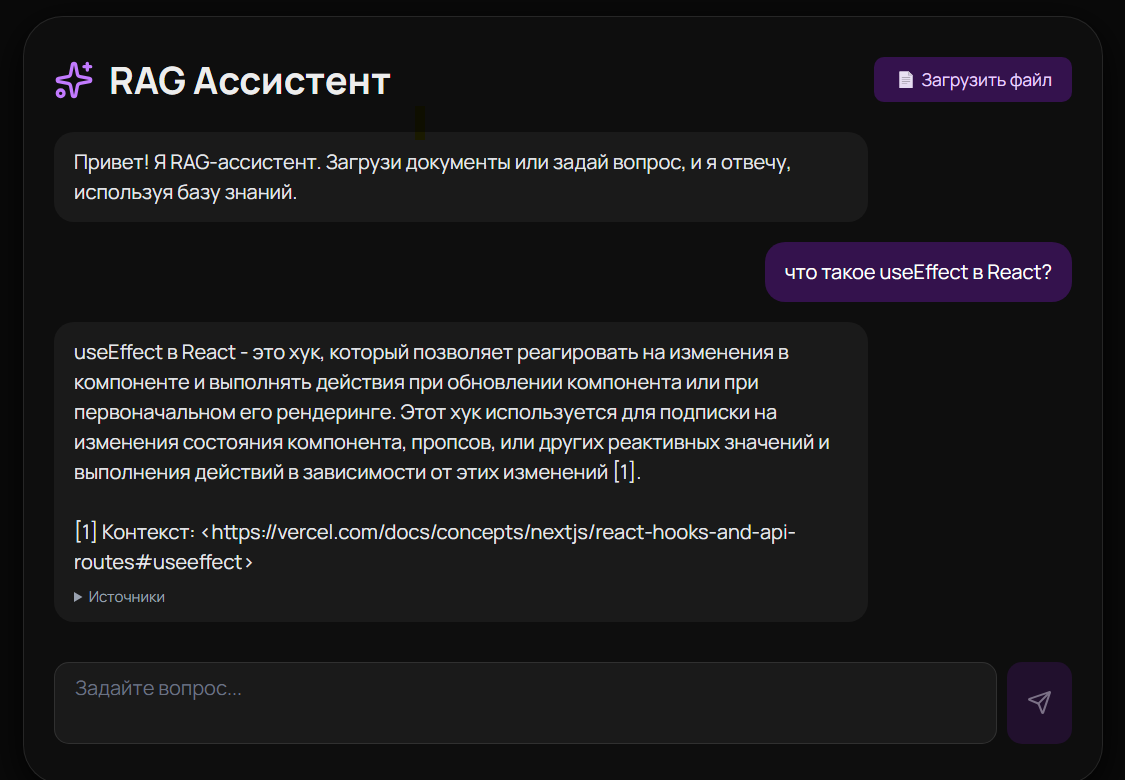
Скриншот
📦 GitHub
Репозиторий: github.com/dmironovru/rag-portfolio
Локальный AI-помощник. Никаких облачных API — все данные остаются на твоём компьютере.
🚀 Быстрый старт
git clone git@github.com:dmironovru/rag-portfolio.git
cd rag-portfolio
./start.sh
# Открой: http://localhost:3000
Скрипт сам проверит зависимости, скачает модели (~4.5 ГБ), создаст базу и поднимет всё окружение. Первый запуск — 10-15 минут, повторные — 30 секунд.
Что за проект
Это AI-ассистент, который отвечает на вопросы по технической документации. Но не просто «спросил у ChatGPT» — он ищет ответы в реальных документах через векторный поиск и генерирует связный ответ через локальную языковую модель.
Архитектура называется RAG (Retrieval-Augmented Generation):
- Ты задаёшь вопрос
- Система находит релевантные куски документации (чанки) через векторный поиск
- Локальная LLM (Mistral 7B) генерирует ответ на основе найденных кусков
- Ты получаешь ответ с цитатами и ссылками на источники
Главная фишка — всё работает локально. Никаких OpenAI API, никаких ключей, никаких утечек данных. Документация и модель лежат на твоём компьютере.
Что использовал
Frontend: Next.js 16, React 19, Tailwind CSS
Backend: Go 1.23, chi, pgx
AI: Ollama (mistral:7b + nomic-embed-text)
Database: PostgreSQL 16 + pgvector (векторное расширение)
Infra: start.sh, Makefile
Пример кода: векторный поиск
Самое интересное — это как работает поиск. Документация разбивается на чанки, каждый чанк превращается в вектор (эмбеддинг) и сохраняется в PostgreSQL с расширением pgvector.
Когда приходит вопрос, он тоже превращается в вектор, и мы ищем ближайшие по косинусному расстоянию:
func (s *Store) Search(ctx context.Context, queryVec []float32, limit int) ([]Chunk, error) {
// Превращаем вектор в строку для SQL
vecStr := "[" + strings.Trim(strings.Join(strings.Fields(fmt.Sprint(queryVec)), ","), "[]") + "]"
query := `
SELECT id, content, source, url,
1 - (embedding <=> $1::vector) AS similarity
FROM chunks
WHERE 1 - (embedding <=> $1::vector) > 0.3
ORDER BY embedding <=> $1::vector
LIMIT $2
`
rows, err := s.pool.Query(ctx, query, vecStr, limit)
// ... обработка результатов
}
Оператор <=> — это косинусное расстояние в pgvector. Чем ближе к 0, тем больше похожи векторы. Фильтр > 0.3 отсеивает совсем нерелевантные куски.
С чем столкнулся
1. Выбор модели
По умолчанию стоит mistral:7b — быстрая и качественная на английском. Но для русских вопросов лучше работает qwen2.5:7b. Сделал переключение через .env:
LLM_MODEL=qwen2.5:7b # Для вопросов на русском
2. Размер моделей
Модели весят ~4.5 ГБ. При первом запуске ./start.sh сам их скачивает через Ollama. Это долго, но один раз — и дальше всё летает.
3. Блокировка Docker Hub
Как и с Todo Manager, Docker Hub в РФ заблокирован. Решение — зеркало:
// /etc/docker/daemon.json
{
"registry-mirrors": ["https://dockerhub.timeweb.cloud/"]
}
Но для RAG я вообще не стал использовать Docker — слишком много зависимостей (Ollama, PostgreSQL с pgvector, Go, Node). Нативный запуск через ./start.sh оказался стабильнее и проще в отладке.
4. Качество ответов
Сначала ответы были «плавали» — модель выдумывала то, чего нет в документации. Помогло:
- Увеличить размер чанков при индексации
- Добавить жёсткий промпт: «Отвечай только на основе найденных источников»
- Показывать источники прямо в интерфейсе, чтобы пользователь мог проверить
Как устроена архитектура
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Frontend │ │ Go Backend │ │ Ollama │
│ (Next.js 16) │────▶│ (RAG API) │────▶│ (LLM) │
│ :3000 │ │ :8080 │ │ :11434 │
└─────────────────┘ └────────┬────────┘ └─────────────────┘
│
┌────────────▼────────────┐
│ PostgreSQL + pgvector │
│ ~1800 чанков доков │
└─────────────────────────┘
- Frontend — чат-интерфейс на Next.js с тёмной темой
- Backend — Go-сервер, который принимает вопрос, ищет чанки, отправляет их в LLM
- Ollama — локальный движок для LLM и эмбеддингов
- PostgreSQL + pgvector — хранит чанки и их векторные представления
Как индексируется документация
По умолчанию база пустая. Чтобы добавить документацию React и Next.js:
cd backend
make ingest
Скрипт:
- Скачивает markdown-файлы из официальных репозиториев GitHub
- Разбивает на чанки по ~500 токенов с перекрытием
- Прогоняет каждый чанк через
nomic-embed-text(модель для эмбеддингов) - Сохраняет в PostgreSQL вместе с вектором
Получается ~1800 чанков. Поиск по ним работает мгновенно.
Планы на развитие
- ✅
Базовый RAG с векторным поиском— сделано - ✅
Умный скрипт запуска— сделано - Добавить загрузку PDF и своих документов через UI
- Поддержать несколько моделей одновременно
- История диалогов с контекстом
- Веб-интерфейс для управления источниками
Если коротко
RAG — это не так страшно, как кажется. Главная сложность — не код, а понимание процесса: как разбивать текст, как выбирать модель, как настраивать промпты.
Самое крутое — когда задаёшь вопрос и видишь, что ассистент не выдумывает, а цитирует реальные куски документации со ссылками. Это совсем другой уровень по сравнению с обычным чат-ботом.
Совет: если хочешь разобраться в AI-разработке — начни с RAG. Это проще, чем файн-тюнинг, и даёт реальный результат. А локальные модели (Ollama) позволяют экспериментировать бесплатно и без ограничений.